
Your Guide to Using a Proxy IP Rotator for Web Scraping
A proxy IP rotator is a tool that automatically cycles through a pool of IP addresses, assigning a new one for each connection you make. Distributing your traffic this way keeps each individual IP comfortably within a site's per-IP rate limits, which is the key to scaling up your data collection reliably and reducing failed requests.
A quick note on authorized use: this guide assumes you are collecting public data you have permission to access, in line with each site's terms and applicable law.
Why You Need an IP Rotator
Imagine you’re a market researcher, and your job is to check the prices of 10,000 products on a competitor's e-commerce site. If you send all those requests from a single home or office IP address, you’ll quickly exceed that site's per-IP rate limit. The result is a wave of HTTP 429 (Too Many Requests) and HTTP 403 responses, extra bot detection challenges, and incomplete data.
This is exactly the problem a proxy IP rotator is built to solve. Instead of routing every request through one address, a rotator distributes them across a pool and automatically swaps the IP for each request. One request might come from an IP in Chicago, the next from Dallas, and the one after that from Miami. Spreading the load this way keeps each IP within the site's rate limits, so your success rate stays high and your data collection runs without interruption.
The Foundation of Scalable Data Collection
At its core, an IP rotator is just a system that manages a pool of proxy servers and intelligently routes your web traffic through them. This process is absolutely fundamental for any serious data gathering operation. To really get why this matters, it's helpful to understand the basics of how to change your IP address. Once you see what that involves, it becomes obvious why doing it manually is completely impractical for large-scale tasks.
A rotator handles this whole process for you, making it seamless and incredibly efficient. This technology is a game-changer for several key activities:
-
Web Scraping: Gathering product details, pricing information, and user reviews while staying within each site's rate limits.
-
SEO Monitoring: Tracking keyword rankings from different geographic locations to get accurate, unbiased search engine results.
-
Ad Verification: Making sure that digital ads are being displayed correctly and to the right audience in the right places.
-
Market Research: Collecting large datasets on consumer trends and competitor strategies at a sustainable pace.
A proxy IP rotator helps you stay within per-IP rate limits by distributing requests across many addresses. This spreads the load so no single IP receives more traffic than a site expects, which keeps your operations stable and scalable.
The demand for this kind of tooling is growing steadily. The rotating proxy service market is expected to reach $2.5 billion by 2025 and is projected to expand at roughly 18% annually through 2033. This reflects how central the technology has become in data-driven industries. Without a rotator, most large-scale data projects would hit rate limits and stall.
Choosing the Right Type of Rotating Proxy
Picking the right proxy IP rotator is a lot like choosing the right tool for a job. You wouldn't use a sledgehammer to hang a picture frame, right? In the same way, the proxy you choose has to match what your web scraping project demands. Not all proxies are built the same.
Your decision will almost always boil down to one of three main categories: datacenter, residential, or mobile proxies. Each one has a different origin story and, as a result, a different level of trust with the websites you’re trying to reach.
Datacenter Proxies: The Business District
Datacenter proxies are the most common and budget-friendly option out there. These IPs aren't linked to a home internet connection. Instead, they're created in bulk by cloud providers and data centers.
Think of them as coming from a big, well-known office building. They're fast, reliable, and cost-effective, which makes them a good fit for simple tasks where speed matters most and the target website applies lighter verification. Because their IP ranges are clearly tied to data centers, they are also the most likely to hit stricter rate limits.
Residential Proxies: The Suburban Neighborhood
Next up are residential proxies. These use real IP addresses assigned by Internet Service Providers (ISPs) to actual homes. When your request goes through a residential proxy, it originates from a normal consumer IP rather than a data center range.
Because these are genuine ISP-assigned addresses, they tend to be treated like ordinary visitor traffic and are well suited to e-commerce sites, social media platforms, and other targets with strict bot detection systems. The market reflects this; with over 5.5 million residential IPs available, they make up 44% of all proxy usage because they work well across a wide range of sites.
This diagram breaks down how a request moves from you, through the rotator which picks an IP, and finally to the target.
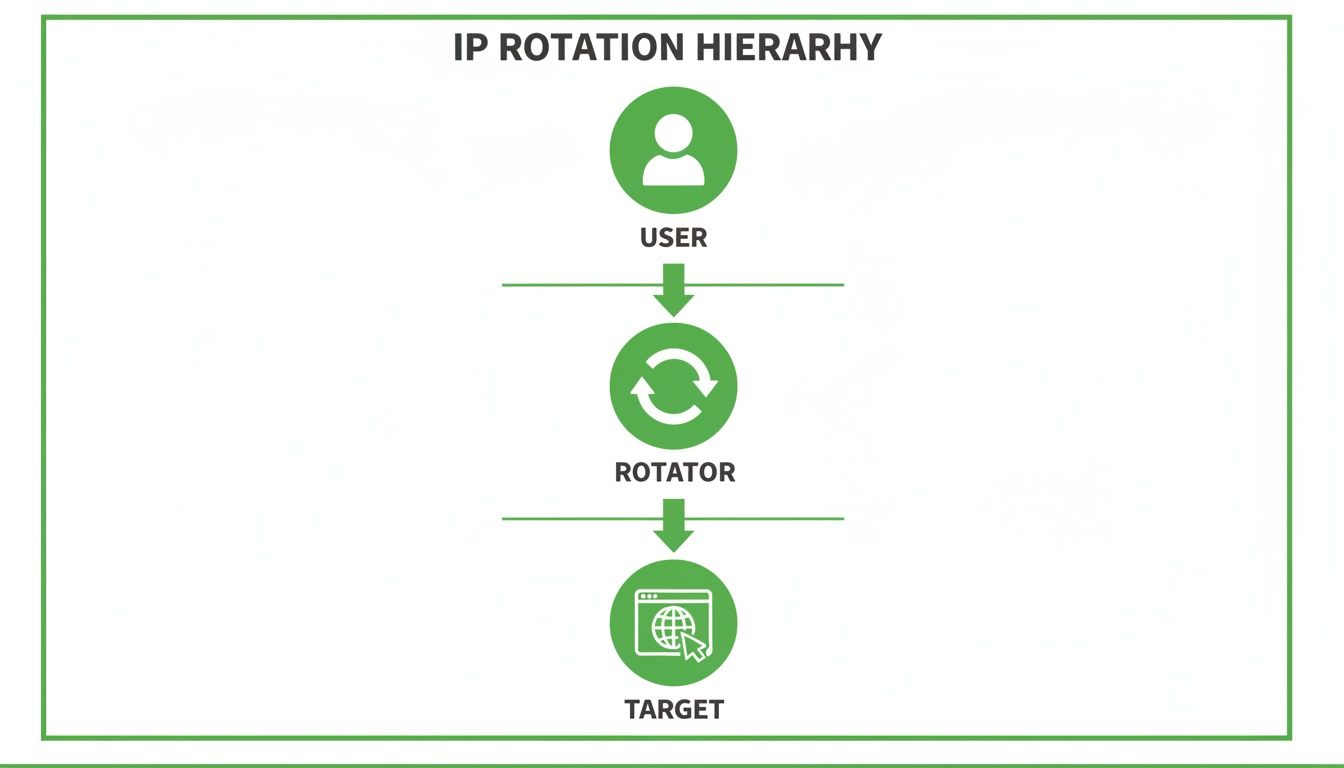
The rotator does the heavy lifting here, acting as an intelligent layer that handles all the IP management for you.
Mobile Proxies: The On-The-Go Connection
Mobile proxies are the top-tier option. They use IP addresses assigned to mobile devices on cellular networks like 4G or 5G. Because mobile carriers share a pool of dynamic IPs across many real users, these addresses are rarely subject to tight per-IP rate limits.
Imagine your request coming from a smartphone moving through a city. The IP is temporary and carrier-assigned, so it sits naturally within normal mobile traffic. This makes mobile proxies a strong choice for mobile-only content or for sites with the strictest bot detection systems.
To make this crystal clear, let's compare these three proxy types side-by-side.
Comparing Datacenter vs Residential vs Mobile Proxies
This table gives you a quick, at-a-glance comparison to help you figure out which proxy type best fits your web scraping or data collection needs.
| Feature | Datacenter Proxies | Residential Proxies | Mobile Proxies |
|---|---|---|---|
| Origin | Cloud data centers | Real home ISPs | Mobile carrier networks |
| Cost | Low | Medium to High | High |
| Speed | Very Fast | Fast | Moderate |
| Rate-limit tolerance | Low | High | Very High |
| Use Case | High-volume, lightly verified targets | E-commerce, social media, complex sites | Mobile-specific content, strictest targets |
| Failed-request risk | High | Low | Very Low |
Ultimately, the right choice depends on balancing performance, cost, and the rate limits and verification your target site applies.
For a deeper dive into specific providers and what they offer, check out our comprehensive guide to the best proxy services for 2025. It’ll help you line up your goals and budget with the perfect proxy IP rotator and provider.
Mastering IP Rotation and Session Management
Having a large pool of IPs is one thing, but the real value of a proxy IP rotator comes from knowing how and when to switch them. Your strategy depends entirely on what you're trying to accomplish, and getting this right is what keeps your request load distributed evenly and your success rate high.

There are two main ways to handle your IP rotation and sessions, and they're built for completely different jobs. Nailing the difference between high-frequency rotation and sticky sessions can be the deciding factor between a successful data pull and a total failure.
High-Frequency Rotation for Simple Tasks
The most straightforward method is high-frequency rotation. This is where your proxy service gives you a fresh, new IP address for every single request you make. Think of it like sending thousands of anonymous postcards, each one dropped into a different mailbox in a different city.
This approach is ideal for simple, one-and-done data requests. Since every request comes from a different IP, the load is spread thin and no single address gets close to a site's per-IP rate limit.
This strategy is your go-to for tasks like:
-
Scraping product listings: Every product page can be treated as a standalone request.
-
Aggregating search engine results: Each keyword search is its own independent action.
-
Collecting public data points: When you just need to grab thousands of disconnected bits of information fast.
When your task doesn't need context or a sequence of actions, high-frequency rotation is the simplest option. It spreads your requests across the largest number of IPs, keeping each one well within rate limits.
But this method hits a wall when you need to perform a series of actions that have to be linked together, like navigating a checkout process. For that, you need a different game plan.
Sticky Sessions for Complex Workflows
For more complicated jobs, you need what we call a sticky session. This approach tells your proxy rotator to hang onto the same IP address for a specific amount of time or for a certain number of requests. Instead of sending all those anonymous postcards, you're now having a consistent conversation from one recognizable spot.
Imagine trying to shop online. You add something to your cart, click over to another page to look at similar items, and then head to checkout. If your IP address changed with every click, the website would see each action as coming from a brand-new person. Your shopping cart would empty itself, you'd get logged out, and the whole thing would fall apart.
A sticky session fixes this by making sure all the requests in a single user journey come from the same IP. It keeps the session intact, letting you perform multi-step actions without a hitch.
This is absolutely essential for:
-
Navigating through multi-step forms
-
Filling out multi-page applications
-
Managing an online shopping cart
-
Interacting with any site that depends on session cookies
For developers putting this into practice, managing session data is key. You can dig into the technical side of this by checking out how Scrappey manages sticky sessions through its API.
Keeping Your Request Signals Consistent
A well-formed request is more than just an IP address. Bot detection systems also read your user agent, request headers, and cookies, so these signals need to be internally consistent.
Your user agent tells a website what browser and operating system you’re on (like Chrome on Windows 11). Your headers add more context, like your preferred language. If your IP address moves from a residential connection in Texas to one in California while your user agent and headers stay tied to a single, mismatched profile, the request looks inconsistent and is more likely to fail.
Proper session management means coordinating these elements along with your IP so each session presents a coherent, well-formed profile. Keeping your signals consistent is what makes large-scale collection reliable and reduces failed requests.
How to Work With Bot Detection Systems
Using a proxy IP rotator is a major first step, but modern websites read far more than just the IP address. To collect data reliably, your requests need to be well-formed and internally consistent across every signal they send. This means going beyond simple IP rotation and managing the full set of request attributes coherently.
Bot detection systems are designed to evaluate how a request is made, not only where it comes from. If you send many requests from a pool of clean residential IPs but they all carry the exact same browser signature, the mismatch between varied IPs and an identical fingerprint produces inconsistent signals and more failed requests.
Keeping Your Request Attributes Coherent
Every request your browser sends carries dozens of data points. The goal is to coordinate these elements so they form a consistent, well-formed profile rather than a contradictory one.
The three most critical components you need to manage are:
-
User Agents: This is a string of text that tells the server which browser (like Chrome or Firefox) and operating system (Windows 10, macOS) you’re using. Sending thousands of requests with a single static user agent that doesn't match the rest of your profile produces inconsistent signals.
-
Request Headers: Headers provide extra context. Things like the language you prefer (Accept-Language), the previous page you visited (Referer), and how your browser handles data (Accept-Encoding). Sending realistic, consistent headers is essential for well-formed requests.
-
Browser Fingerprints: This is a more advanced area where websites collect a combination of your browser's attributes—installed fonts, screen resolution, active plugins, and subtle hardware details. These should stay coherent with the rest of your request profile.
This diagram shows how these different data points combine into a request profile. Reliable collection means keeping every part of this cycle consistent.
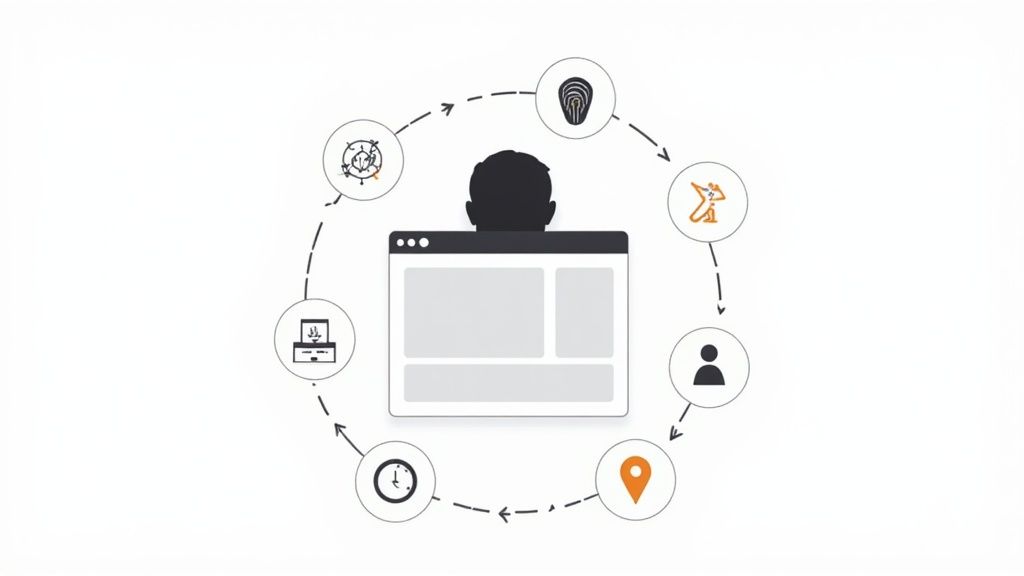
Managing this entire data cycle consistently is what keeps your collection reliable and your failed-request rate low.
Pacing Requests Like Well-Behaved Automation
Reliable automation is about more than data—it’s about etiquette. Good automation doesn't fire 50 page requests in five seconds. It paces itself, leaves room between requests, and honors the server's signals. Your scraper should do the same.
The goal is to be a well-behaved client: sensible request pacing, controlled concurrency, and respect for the server's capacity. This means adding deliberate delays between requests and avoiding bursts that overwhelm the site.
To put this into practice, add reasonable delays between your requests. Instead of a fixed two-second wait, vary it within a sensible range, say one to five seconds, and keep concurrency modest. This keeps your traffic gentle on the server and helps you stay within rate limits.
Why CAPTCHAs Appear and How to Respect Them
You may occasionally run into a CAPTCHA. These "Completely Automated Public Turing tests to tell Computers and Humans Apart" usually appear when a site sees more traffic from a source than it expects, or when request signals look inconsistent. The right response is to respect them rather than treat them as an obstacle.
If you hit CAPTCHAs frequently, slow down your request pace, reduce concurrency, and make sure your request profile is consistent. For higher-volume needs, the best path is to request official API access or another authorized arrangement with the site. Distributing requests across IPs and keeping your signals well-formed reduces how often CAPTCHAs appear in the first place.
Geo-Targeting for Precision and Accuracy
Sometimes, the data you need is specific to a certain country, state, or even city. Geo-targeting is a feature that premium proxy services offer, allowing you to send requests from a specific geographic location.
This gives you two major benefits:
-
Accessing Localized Content: You can scrape search results exactly as they appear to users in Germany, or check product prices on an e-commerce site as they're shown to customers in New York.
-
Geographic Consistency: If you're collecting data from a UK-based website, sending requests from a pool of UK residential proxies keeps your IP origin consistent with the locale you're requesting, which improves data accuracy.
By combining a robust proxy IP rotator with careful management of your full request profile—from headers and fingerprints to timing and location—you can build a scraper that is resilient, reliable, and consistent across bot detection systems. To better understand how websites read your connection's signature, see our detailed guide on what is TLS fingerprinting. This deeper understanding will help you keep your request signals well-formed.
Putting Your Proxy IP Rotator into Action
Alright, let's move from theory to reality. Understanding how a proxy IP rotator works is one thing, but actually plugging it into your web scraping scripts is where the magic happens. This is the moment you turn strategy into code and start pulling in the data you need, efficiently and reliably.
The whole process usually starts when you sign up with a good proxy provider. They’ll typically give you a single endpoint—just one address and port—that acts as a gateway to their entire pool of IP addresses. When you point your requests at this endpoint, their system takes care of all the heavy lifting, swapping out your IP based on the rotation rules you’ve set.
Basic Integration with Python
For most developers, the first step is a simple Python script. Using the incredibly popular requests library, getting a basic rotator up and running is surprisingly straightforward. All you need to do is format your proxy credentials and tell your request to use them.
Here’s a bare-bones example to show you how to route a request through a proxy endpoint.
import requests
Your proxy service credentials and endpoint
proxy_endpoint = 'http://username:password@proxy.example.com:8080'
proxies = { 'http': proxy_endpoint, 'https': proxy_endpoint, }
target_url = 'https://api.ipify.org?format=json' # A simple site to check your IP
try: response = requests.get(target_url, proxies=proxies, timeout=10) response.raise_for_status() # Raises an exception for bad status codes (4xx or 5xx) print(f"Success! Response from IP: {response.json()['ip']}") except requests.exceptions.RequestException as e: print(f"An error occurred: {e}")
This script gets a basic connection going, but a real-world scraper needs to be more resilient. To collect data reliably, you have to anticipate connection failures, handle timeouts, and set consistent, realistic request headers.
A More Robust Scraping Example
A script you'd use in production needs to be much more resilient. It should gracefully handle failed requests and include realistic, consistent headers that match a real browser. Well-formed headers are the foundation of reliable requests that pass bot detection systems cleanly.
Take a look at this more advanced implementation:
import requests import random
def scrape_with_rotating_proxy(url): proxy_endpoint = 'http://username:password@proxy.example.com:8080' proxies = {'https': proxy_endpoint, 'http': proxy_endpoint}
# Use realistic, current User-Agent strings for well-formed requests
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15',
]
headers = {'User-Agent': random.choice(user_agents)}
try:
response = requests.get(url, proxies=proxies, headers=headers, timeout=15)
if response.status_code == 200:
print(f"Successfully fetched {url}")
return response.text
else:
print(f"Failed with status code: {response.status_code}")
return None
except requests.exceptions.Timeout:
print("Request timed out.")
return None
except requests.exceptions.ProxyError:
print("Proxy error. The proxy may be down or misconfigured.")
return None
This improved function is far more reliable for real tasks because it adds header rotation and specific error handling. If you want to dive deeper into the entire web scraping process, check out this complete guide on how to extract data from websites.
The Power of Integrated Scraping APIs
While building your own rotator logic gives you total control, it also adds a ton of complexity. Suddenly you’re responsible for managing IP health, error retries, header rotation, and browser fingerprints. This is exactly where fully integrated solutions like Scrappey come in and save the day.
An integrated web scraping API abstracts away the entire proxy management layer. You make a simple API call to your target URL, and the service handles the rest—IP rotation, session handling, and consistent request profiles—behind the scenes.
This approach frees you up to focus on what you actually care about: parsing the data you need, not maintaining the plumbing that fetches it. The market for these managed tools is growing for a reason. The global rotating proxy solution market is projected to reach $3.5 billion by 2031, driven by demand for systems that handle this complexity automatically.
Ultimately, whether you build it yourself or use a ready-made API, putting a proxy IP rotator into action is a key step toward scalable, reliable data collection.
Navigating the Legal and Ethical Rules of Web Scraping
A proxy ip rotator gives you incredible power to gather data, but that power comes with a serious responsibility to play by the rules. It’s easy to get caught up in the technical side of things, but the line between legitimate data collection and malicious activity is all about respect, transparency, and following the rules of the road.
Think of it like being a guest in someone's digital home—you have to follow their house rules.
The first, and most important, rule is to read and respect a website's Terms of Service (ToS). This document spells out exactly what is and isn't allowed, often including specific clauses about automated data collection. Blowing past the ToS isn't just bad form; it can land you in legal hot water. Always check it before you start scraping.
Understanding Key Guidelines
Beyond the ToS, the robots.txt file is your next stop. This simple text file, sitting at the root of most websites, is a direct message to bots, telling them which pages they can visit and which are off-limits. Following these instructions is a basic tenet of ethical scraping and shows you’re acting in good faith.
Here are the core principles every responsible scraper should live by:
-
Respect robots.txt: Always check this file and follow its directives. It’s the clearest instruction a site owner can give to automated traffic.
-
Adhere to Terms of Service: Never scrape in a way that violates a site's explicit terms. Consider this your primary legal and ethical guide.
-
Avoid Overloading Servers: Scrape at a reasonable pace. Hammering a site with too many requests too quickly can crash their servers, ruining the experience for human users. Even if it's unintentional, it can look like a denial-of-service attack.
-
Identify Your Scraper: When you can, set a descriptive user agent for your scraper. This bit of transparency helps site admins understand where the traffic is coming from and what it's for.
Complying with Data Privacy Laws
Things get a lot more serious when personal data enters the picture. Regulations like Europe's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) have strict rules about how personal information is collected, handled, and stored.
A critical lesson for any data professional is this: just because data is publicly visible doesn't mean it's a free-for-all. Privacy laws still apply.
Violating these regulations can lead to massive fines and destroy your reputation. You have to make sure your data collection practices are fully compliant with the privacy laws in the regions you're targeting. That means knowing what counts as personal data and treating it with the care it requires.
By using your proxy ip rotator ethically and responsibly, you’re not just dodging legal bullets—you’re building a reputation as a professional who respects the digital ecosystem.
Frequently Asked Questions About Proxy IP Rotators
Jumping into the world of proxy IP rotators can bring up a few questions, especially when you're just starting out. Let's clear the air and tackle some of the most common ones we hear.
How Many Proxies Do I Need?
The honest answer? It completely depends on your project. The two big factors are the website you're targeting and how many requests you need to make. For a small-scale scrape on a site that’s not too strict, a pool of a few dozen IPs might do the trick.
But if you’re running a large-scale operation against a heavily protected platform, you'll need a much larger pool. We're talking thousands, or even millions, of IPs so you can distribute load widely, keep each IP within per-IP rate limits, and maintain a high success rate.
Can a Rotator Guarantee I Won't Hit Rate Limits?
While a proxy IP rotator significantly lowers your chances of running into HTTP 429 and HTTP 403 responses, it's not a silver bullet. Bot detection systems look at more than IP addresses; they also evaluate request headers, fingerprints, and request pacing.
A reliable strategy is about more than switching IPs. Combine rotation with consistent, well-formed requests—realistic user agents, correctly managed headers, and sensible delays between requests. The aim is a coherent, well-behaved request profile that stays within each site's limits.
What Is the Difference Between a Proxy Rotator and a VPN?
This is a really common point of confusion, but they’re built for fundamentally different jobs. Think of a VPN as a personal privacy shield. It’s designed to route all the traffic from your single device through one secure server, keeping your identity safe.
A proxy IP rotator, on the other hand, is a specialized tool built for automation at scale, like web scraping. It's not about one device; it’s about managing a massive pool of IPs and swapping them out for individual requests. This allows you to handle a volume of tasks that a VPN simply isn't designed for.
Ready to stop worrying about proxy management and focus on your data? Scrappey handles the complexity of IP rotation, session handling, and consistent request profiles for you. Start collecting the data you're authorized to access with our API today.