
The Top 12 ScrapingBee Alternative Tools for 2025
Finding the right web scraping API is critical for building reliable and scalable data extraction pipelines. While ScrapingBee is a popular choice, its pricing, feature set, or specific capabilities might not be the perfect fit for every project. Your specific needs, whether it's large-scale e-commerce price monitoring, SERP data collection, or complex JavaScript-heavy site navigation, demand a tool tailored to the task. This guide is designed to help you navigate the landscape and find the best ScrapingBee alternative for your exact use case.
We will dive deep into twelve leading web scraping platforms, providing a comprehensive analysis that goes beyond surface-level feature lists. Each entry includes a practical overview, detailed pros and cons, specific pricing notes, and ideal use-case scenarios to help you make an informed decision. You will find API code snippets, direct links, and screenshots to give you a clear picture of each tool's functionality and user experience.
Choosing the right tool often involves evaluating several options, whether you're building a data pipeline or need a different kind of software. For instance, if your workflow also involves creating documentation or tutorials, you might find yourself exploring various free Snagit alternatives for screen capture to find one that fits your process. Similarly, this listicle provides a focused comparison to help you select a web scraping solution. Our goal is to equip you with the necessary information to confidently choose a platform that aligns with your technical requirements, budget, and project goals, and to streamline any potential migration. Let's explore the top alternatives available today.
1. Scrappey
Best For: Engineering and analytics teams requiring a reliable, high-throughput web scraping API with minimal maintenance.
Scrappey presents itself as a formidable ScrapingBee alternative for developers who need a production-ready, scalable data extraction solution. It’s engineered to tackle the most common and frustrating aspects of web scraping, such as dynamic JavaScript-heavy websites and sophisticated bot detection countermeasures. The platform’s core value lies in its ability to abstract away the complexity of managing proxies and headless browsers, allowing teams to focus on data utilization rather than scraper maintenance.
This focus on operational reliability makes Scrappey an excellent choice for business-critical workflows where data freshness and consistency are paramount. Its architecture, featuring smart queueing, automatic retries, and webhook support, is built to sustain high-volume data pipelines without constant manual intervention.
Key Strengths and Features
Scrappey's design prioritizes developer experience and robust performance, making it a powerful tool for scaling data collection efforts.
-
Advanced Session Handling: The platform integrates rotating residential and datacenter proxies, headless browser rendering, and automated session handling. This multi-layered approach significantly increases success rates against demanding sites.
-
Developer-Focused API: With a clean REST API and available client libraries, integration is straightforward. Developers can easily manage sessions for multi-step scraping tasks, apply geo-targeting for localized content, and set custom headers to match a real browser profile behavior.
-
Reliable High-Volume Scraping: Scrappey is built for scale. Features like concurrency controls, intelligent request queueing, and webhook notifications for asynchronous jobs ensure that large-scale data extraction projects run smoothly and efficiently.
-
Business Use-Case Alignment: The platform is particularly effective for common commercial applications such as e-commerce price monitoring, SEO rank tracking, market research, and lead generation, where accuracy and speed are critical.
Pricing and Onboarding
Scrappey does not list public pricing tiers on its website. Prospective customers must contact the sales team for a custom quote. This approach suggests a focus on tailored enterprise or high-volume plans. When evaluating, be sure to request customer references or performance benchmarks to validate its capabilities for your specific use case.
Website: https://scrappey.com
2. Zyte
Zyte (formerly known as Scrapinghub) is a comprehensive web scraping platform built for engineering teams that require robust, scalable, and reliable data extraction. As a powerful ScrapingBee alternative, Zyte distinguishes itself with an enterprise-grade focus, strong documentation, and a unique, success-based pricing model. It's an excellent choice for businesses that need granular control over their scraping operations and predictable costs, especially at scale.
The platform centers on the Zyte API, which handles everything from proxy rotation and browser rendering to ban detection and session handling. This allows developers to focus on parsing logic rather than the complex infrastructure required for accessing.
Key Features & Pricing
Zyte's most compelling feature is its success-based billing, meaning you only pay for successful 2xx responses, which significantly de-risks large-scale projects. Pricing is structured in tiers based on request volume and the complexity of the target website (e.g., standard, medium, or high difficulty).
-
Pricing: Starts at $25/month for 50,000 standard requests, with automatic volume discounts as usage increases. Higher-tier plans offer increased concurrency and dedicated support.
-
Request Modes: Supports both raw HTML (unrendered) and full browser rendering for JavaScript-heavy sites.
-
Accessing: Advanced session handling for even the most difficult targets.
Pros and Cons
| Pros | Cons |
|---|---|
| Only pay for success; failed requests are not billed. | Pricing model can be complex to master initially. |
| Enterprise-grade documentation and support. | Scraping high-difficulty websites can become costly. |
| Highly scalable with strong performance. | Learning curve is steeper than simpler APIs. |
Best Fit For
Zyte is ideal for established engineering teams and large enterprises that need a reliable, fully-managed scraping infrastructure for mission-critical data. It excels in scenarios requiring high success rates against complex, heavily protected websites where the cost of failure is high.
Website: https://zyte.com
3. Oxylabs
Oxylabs is an enterprise-focused data extraction platform renowned for its premium proxy infrastructure and specialized Scraper APIs. As a robust ScrapingBee alternative, it caters to businesses that require high-volume, reliable data collection from challenging targets like search engines and e-commerce giants. Its primary strength lies in providing a stable, scalable, and versatile solution backed by one of the largest proxy pools in the market.
The platform offers a suite of tools, including a Web Scraper API, SERP Scraper API, and E-Commerce Scraper API, each optimized for its specific domain. This approach allows developers to leverage a finely-tuned tool for their exact use case, whether it's gathering search results, product data, or general web content, while the underlying infrastructure handles JavaScript rendering, proxy rotation, and accessing.
Key Features & Pricing
Oxylabs' key differentiator is its combination of a powerful, all-in-one Web Scraper API with dedicated APIs for common high-value targets. The platform provides transparent pricing based on successful requests and includes JavaScript rendering in its core offering, ensuring dynamic sites are handled effectively.
-
Pricing: Web Scraper API plans start at $49/month for 25,000 successful requests. Pricing varies for specialized SERP and E-Commerce APIs, with free trials available for testing.
-
Target-Specific APIs: Offers dedicated endpoints for Google, Amazon, and other major platforms for optimized performance and data parsing.
-
Infrastructure: Built on a massive, premium proxy network, ensuring high success rates and global coverage.
Pros and Cons
| Pros | Cons |
|---|---|
| Excellent reliability and scale for large projects. | Can be more expensive than competitors for small-scale use. |
| Specialized APIs for complex targets like SERPs. | Advanced features are often reserved for higher-tier plans. |
| Free trial options to validate performance. | The variety of products can be complex to navigate initially. |
Best Fit For
Oxylabs is best suited for large-scale data operations, business intelligence teams, and enterprises that need a dependable data partner for mission-critical scraping. It is particularly effective for projects focused on SEO monitoring, price intelligence, and market research where data accuracy and uptime from difficult sources are paramount.
Website: https://oxylabs.io
4. Bright Data
Bright Data is a vast data collection platform offering a wide array of tools that position it as a comprehensive ScrapingBee alternative for enterprises. It provides managed accessing with its Web Unlocker, a Scraping Browser for interactive automation, a powerful Web Scraper API, and even a marketplace for pre-collected datasets. This multi-product approach makes it a strong contender for teams needing a flexible, all-in-one solution for complex data extraction challenges at scale.
The platform is built on one of the world's largest proxy networks, which underpins its powerful accessing capabilities. This allows developers to choose between a fully managed API that handles proxy rotation and retry handling, or a more hands-on approach using the Scraping Browser with their existing automation scripts. For a deeper look at their network, you can learn more about their extensive proxy services.
Key Features & Pricing
Bright Data's strength lies in its modularity, allowing users to select the specific tool that fits their use case, from simple API calls to complex browser automation. Billing is flexible, with both pay-as-you-go (PAYG) and monthly/yearly commitment plans available, catering to different project sizes and budget predictability needs.
-
Pricing: PAYG starts at $10/CPM for the Web Unlocker, with rates decreasing significantly with monthly commitments. A pricing calculator is available for estimates.
-
Web Unlocker: A fully managed API for accessing that handles all IP rotation, fingerprinting, and session handling automatically.
-
Scraping Browser: A Puppeteer/Playwright-compatible browser API for automating complex user interactions on JavaScript-heavy sites.
Pros and Cons
| Pros | Cons |
|---|---|
| Very large proxy/IP footprint and a broad suite of tools. | Pricing can be premium compared to SMB-focused tools. |
| Mature enterprise support and excellent documentation. | Some specific pricing details require contacting sales. |
| Choice of API- or browser-driven collection methods. | The sheer number of products can be overwhelming initially. |
Best Fit For
Bright Data is best suited for large-scale data operations, enterprises, and businesses that require a robust, reliable, and versatile data collection infrastructure. It excels in scenarios where a combination of different scraping methods is needed and where the cost of being blocked is high, justifying the premium investment for top-tier accessing performance.
Website: https://brightdata.com
5. Smartproxy / Decodo
Decodo (formerly Smartproxy) is a versatile data collection platform known for its extensive proxy network and user-friendly scraping APIs. As a strong ScrapingBee alternative, Decodo appeals to a broad audience, from individual developers to mid-sized businesses, by offering flexible pricing and a straightforward onboarding process. The platform is designed to simplify web data extraction with its all-in-one Site Web access tool and dedicated scraper APIs, handling proxy rotation, session handling, and browser rendering automatically.
This approach allows users to focus on data parsing while Decodo manages the accessing infrastructure. Its combination of a massive proxy pool and automated tools makes it a compelling choice for projects that require reliable geo-targeting and high success rates without the enterprise-level complexity of other solutions.
Key Features & Pricing
Decodo's main strength lies in its flexible billing models, which include both pay-per-request and pay-per-GB plans for its Site Web access tool. This allows users to choose the most cost-effective option for their specific use case, whether it involves many small requests or fewer large ones.
-
Pricing: Site Web access tool starts at 75/month for 25GB of traffic or 50 for 50,000 requests. Dedicated scraper APIs for SERP, e-commerce, and social media have their own tiered pricing.
-
Automatic Accessing: Integrates JavaScript rendering, session handling, and intelligent proxy rotation to achieve a claimed 99.99% success rate.
-
Geo-Targeting: Leverages a vast network of residential, mobile, and ISP proxies for precise location-based scraping.
Pros and Cons
| Pros | Cons |
|---|---|
| Flexible billing models (per-GB or per-request). | Pricing matrices can be complex across different products. |
| Easy onboarding and helpful support documentation. | Achieving top throughput speeds may require higher-tier plans. |
| Competitive performance for US and EU targets. | Not as focused on enterprise-level features as some competitors. |
Best Fit For
Decodo is an excellent choice for developers, data analysts, and small-to-medium-sized businesses that need a reliable, easy-to-use scraping solution with predictable costs. It is particularly effective for use cases like SERP monitoring, price intelligence, and ad verification that require robust geo-targeting capabilities without a steep learning curve.
Website: https://decodo.com
6. Apify
Apify is a unique cloud platform that offers a more holistic approach to web scraping and automation, making it a compelling ScrapingBee alternative for those who want more than just an API. It provides a full ecosystem with pre-built scraping tools called "Actors," a robust API, integrated proxies, and data storage, allowing users to quickly deploy and run complex data extraction workflows without managing the underlying infrastructure.
The platform's main strength lies in its Actor-based model. The Apify Store contains thousands of ready-made scrapers for popular websites like Amazon, Google Maps, and social media platforms. This allows teams to get started immediately, while developers can also build, run, and even monetize their own custom Actors on the platform. Understanding the regulations is key, and you can learn more about the legal side of scraping.
Key Features & Pricing
Apify's model combines a free tier with a usage-based system where you purchase "platform credits" to spend on compute units, proxy traffic, and storage. This provides flexibility to scale resource consumption based on project needs.
-
Pricing: A generous Free plan includes 5 in platform credits monthly. Paid plans start at 49/month for $49 in credits, with larger plans offering better credit value and team features.
-
Apify Store: Access a massive library of pre-built "Actors" (scrapers) for countless use cases, significantly reducing development time.
-
Integrated Workflow Tools: Includes built-in schedulers, webhooks, data storage (datasets, key-value stores), and proxy management.
Pros and Cons
| Pros | Cons |
|---|---|
| Fastest way to start scraping using pre-built Actors. | Billing based on compute units can be confusing initially. |
| Strong workflow features and data delivery integrations. | The quality of third-party Actors can vary, requiring testing. |
| Generous free plan for testing and small projects. | Less of a pure API and more of a complete platform. |
Best Fit For
Apify is perfect for developers and businesses that need to deploy scrapers quickly without building everything from scratch. It's also ideal for those who require a full workflow solution, including scheduling, data storage, and integrations, rather than just a simple request-accessing API.
Website: https://apify.com
7. ZenRows
ZenRows offers a unified web scraping toolkit designed for developers who need an all-in-one solution for API access, browser rendering, and proxy management. As a flexible ScrapingBee alternative, it consolidates multiple scraping essentials under a single subscription, simplifying toolchain management. The platform is built to handle common scraping obstacles automatically, including retry handling, IP blocks, and browser fingerprinting, allowing developers to focus more on data parsing.
Its Universal Scraper API combines these features into one endpoint, with a pricing model that transparently adds multipliers for premium features. This approach provides clarity on how costs scale when enabling JavaScript rendering or using premium residential proxies for difficult targets.
Key Features & Pricing
ZenRows' standout feature is its integrated suite, where one plan provides access to its API, a Scraping Browser, and a large proxy pool. It also employs success-based charging for its API, ensuring you only pay for successful requests. Their documentation is clear and developer-friendly, with practical guidance for common scraping challenges.
-
Pricing: A free trial with 1,000 credits is available. Paid plans start at $49/month for 100,000 API credits, with clear cost multipliers for features like JS rendering or premium proxies.
-
Unified Toolkit: One subscription unlocks the Universal API, Scraping Browser, and proxy pool.
-
Accessing: Automatic handling of WAFs, challenges, and geo-targeting.
Pros and Cons
| Pros | Cons |
|---|---|
| Transparent cost multipliers for JS and proxies. | Costs can add up quickly when using premium features. |
| One subscription covers API, browser, and proxies. | Browser/proxy billing can involve GB + time metrics. |
| Free trial with a generous request limit. | Not as focused on enterprise-grade features as some rivals. |
Best Fit For
ZenRows is an excellent choice for developers, startups, and small to medium-sized teams who want a simple, all-in-one scraping solution without juggling multiple subscriptions. It is particularly well-suited for projects that require a mix of simple API calls and full browser rendering against moderately protected websites.
Website: https://www.zenrows.com
8. Crawlbase (formerly ProxyCrawl)
Crawlbase, the platform formerly known as ProxyCrawl, offers a suite of powerful tools for anonymous web crawling and scraping. As a mature ScrapingBee alternative, it stands out with its intelligent Crawling API that automatically handles proxies, browser rendering, and retry handling. This allows developers to focus on data extraction logic rather than the intricate details of handling bot detection measures, making it an excellent choice for teams that value simplicity and reliability.
The service is built around a single, unified API endpoint that adapts its strategy based on the complexity of the target website. This simplifies the development process, as you don't need to switch between different parameters for JavaScript-heavy sites versus static HTML pages; the API manages it for you.
Key Features & Pricing
Crawlbase’s pricing model is a key differentiator, based on the complexity and volume of requests. It offers an intuitive online calculator to estimate costs before committing, and you only pay for successful requests. This approach provides transparency and helps manage budgets effectively.
-
Pricing: Starts with 1,000 free requests. Pay-as-you-go pricing is based on target site difficulty, with standard sites costing 2.99 per 1,000 requests and JavaScript-rendered sites starting at 7.99 per 1,000 requests.
-
Intelligent Accessing: The API automatically detects and handles blocks, including advanced retry handling and browser fingerprinting.
-
Cloud Storage: Offers built-in options to store scraped data directly in cloud storage services like Amazon S3 or Google Cloud.
Pros and Cons
| Pros | Cons |
|---|---|
| Intuitive cost calculator helps estimate expenses. | Exact cost-per-request depends on each site's complexity. |
| Mature API lineage from its ProxyCrawl days. | Advanced controls and parameters may require experimentation. |
| Only pay for success; free credits to test. | Pricing can escalate for very difficult or large-scale targets. |
Best Fit For
Crawlbase is ideal for developers and data teams who need a reliable, "set-and-forget" scraping API that intelligently handles various site complexities. It's particularly well-suited for projects involving diverse targets where manually configuring proxy and rendering settings for each site would be impractical or time-consuming.
Website: https://crawlbase.com
9. ScraperAPI
ScraperAPI is a popular and straightforward web scraping API designed to handle proxy rotation, browser rendering, and retry handling. As a well-regarded ScrapingBee alternative, it simplifies the data extraction process by managing the underlying infrastructure, allowing developers to retrieve raw HTML or rendered content with a simple API call. Its credit-based system and clear pricing tiers make it a predictable and accessible choice for teams of all sizes.
The platform is known for its ease of use and quick integration, offering SDKs for major programming languages and pre-built templates for common scraping targets. This makes it an excellent option for developers who want to get up and running quickly without a steep learning curve.
Key Features & Pricing
ScraperAPI's core value lies in its simplicity and predictable credit-based plans. Each API call consumes a certain number of credits depending on its complexity, such as whether it requires JavaScript rendering or premium proxies. This model provides clear visibility into usage and costs.
-
Pricing: Starts at $49/month for 100,000 API credits. Plans scale up to 5,000,000+ credits, offering more concurrency and features like residential IPs.
-
JavaScript Rendering: Optional JS rendering can be enabled with a simple parameter.
-
Geotargeting: Supports country-specific geotargeting, though lower-tier plans are limited to US and EU regions.
-
SDKs & Templates: Provides official libraries and templates for common data sources to accelerate development.
Pros and Cons
| Pros | Cons |
|---|---|
| Simple, predictable pricing tiers. | Lower-tier plans have limited geotargeting options. |
| Easy onboarding and good language SDKs. | Heavily demanding sites can consume credits quickly. |
| Popular choice with extensive documentation. | Concurrency limits on entry-level plans. |
Best Fit For
ScraperAPI is ideal for startups, small to medium-sized businesses, and developers who need a reliable, easy-to-integrate scraping API with predictable monthly costs. It excels in use cases like price monitoring, lead generation, and market research where speed of implementation and straightforward maintenance are key priorities.
Website: https://www.scraperapi.com
10. Scrapfly
Scrapfly is a developer-centric web scraping API that stands out as a strong ScrapingBee alternative due to its transparent, credit-based pricing model. It's designed for developers who need fine-grained control over their scraping costs on a per-request basis. The platform allows users to explicitly enable features like JavaScript rendering or residential proxies, with each feature adding a predictable credit cost to the API call, ensuring no surprise charges.
This approach gives teams exceptional control over budgets. Developers can set cost limits per API call or for an entire project, preventing accidental overages. Scrapfly’s focus on transparency extends to its monitoring dashboard, which includes powerful replay and debugging tools to help diagnose failed requests quickly.
Key Features & Pricing
Scrapfly's core strength is its adaptive credit system, where API calls are charged based on the features used. A simple HTML request costs a base amount, while enabling JS rendering or premium proxies consumes additional credits. Headers in the API response provide a clear cost breakdown for every request.
-
Pricing: Offers a free plan with 1,000 credits to start. Paid plans start at $29/month for 100,000 credits, scaling up with volume.
-
Cost Control: Set budgets per call and per project to manage spending effectively.
-
Developer Tools: Includes a monitoring dashboard with replay, debugging, and detailed logs.
Pros and Cons
| Pros | Cons |
|---|---|
| Very transparent pricing controls at the feature level. | Credit accounting for features requires some initial learning. |
| Good value at mid-tiers with 1,000 free credits to start. | No pure pay-as-you-go option without a subscription plan. |
| Strong developer documentation with practical examples. | May have fewer advanced features than enterprise-focused tools. |
Best Fit For
Scrapfly is an excellent choice for developers, startups, and small to medium-sized teams who value cost transparency and budgetary control. It's ideal for projects where scraping needs vary, allowing users to pay only for resource-intensive features like browser rendering or residential proxies when absolutely necessary.
Website: https://scrapfly.io
11. SerpAPI
SerpAPI is a highly specialized, real-time Search Engine Results Page (SERP) scraping API. While not a general-purpose tool like many on this list, it serves as a powerful ScrapingBee alternative for users whose primary goal is extracting structured data from Google, Bing, and other major search engines. Its strength lies in providing mature, reliable parsers for various search surfaces, making it a go-to solution for SEO, marketing, and competitive intelligence teams that need consistent SERP data without managing the underlying scraping complexity.
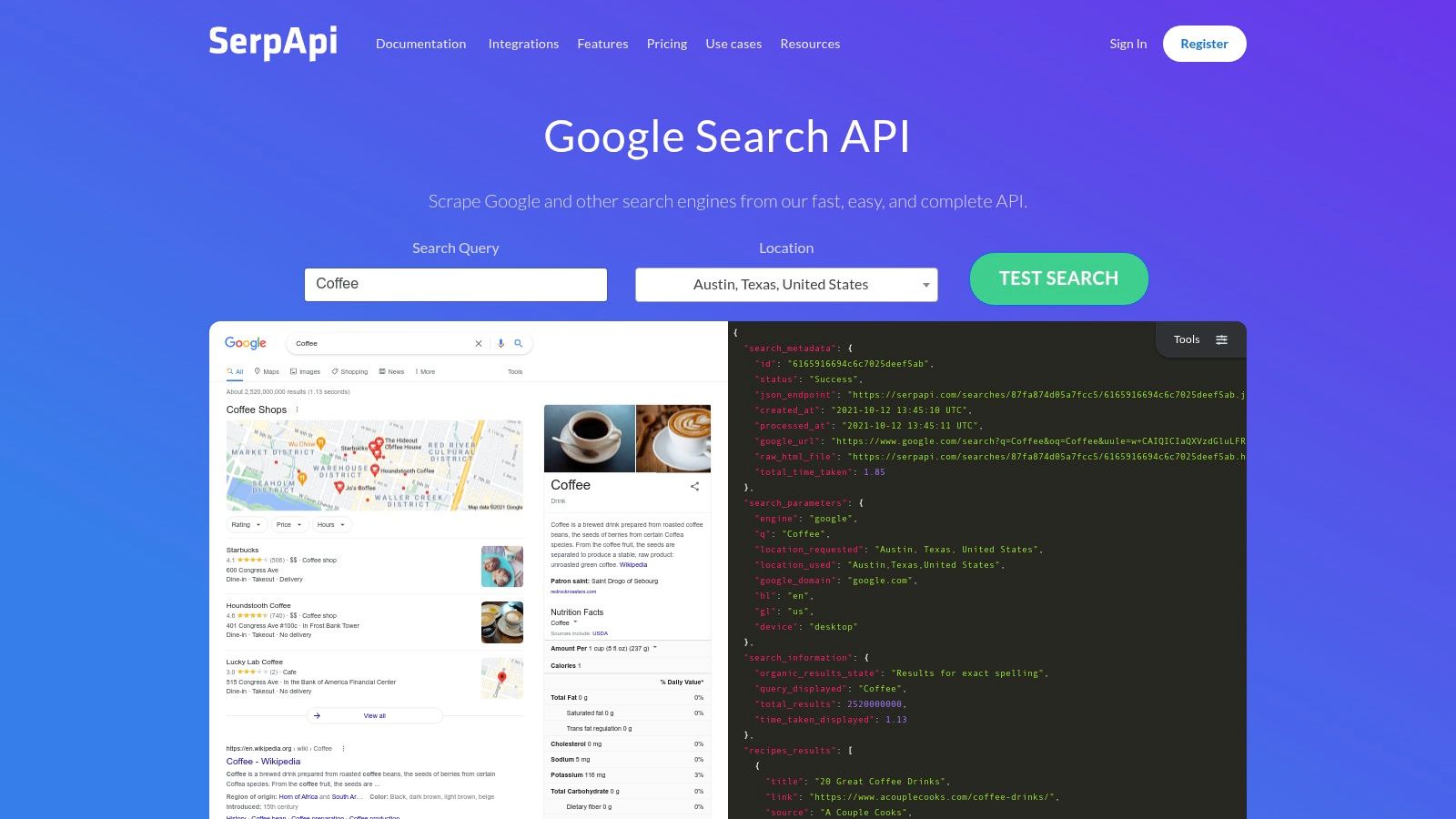
The platform abstracts away the entire process of proxy management, session handling, and browser automation specifically for search engines. It returns clean, structured JSON data for organic results, ads, local packs, shopping results, and more, allowing developers to integrate search data directly into their applications.
Key Features & Pricing
SerpAPI's most significant feature is its extensive coverage of different search types and engines. It simplifies data extraction from complex surfaces like Google Maps, Shopping, Images, and News. The pricing is based on a predictable monthly search quota, which helps with budget forecasting.
-
Pricing: The Developer plan starts at $50/month for 5,000 successful searches. Higher-tier plans offer increased search volumes, higher throughput, and enterprise-level SLAs.
-
Success-Based Counting: You are not billed for cached or errored searches, ensuring you only pay for successfully processed, real-time results.
-
Extensive SERP Coverage: Provides dedicated APIs for a wide array of Google and Bing search verticals.
Pros and Cons
| Pros | Cons |
|---|---|
| Very mature SERP parsers provide reliable, structured data. | Focused only on SERP data; not a general-purpose scraper. |
| Clear monthly quotas make cost forecasting easy. | Cost per search can become high for very large-volume projects. |
| Strong enterprise SLAs and dedicated support options are available. | Less flexible for custom, non-search-engine scraping tasks. |
Best Fit For
SerpAPI is the ideal choice for SEO agencies, marketing analytics platforms, and businesses that rely heavily on accurate, real-time search engine data. It is perfectly suited for rank tracking, ad monitoring, competitive analysis, and any application that requires structured SERP information without the overhead of building and maintaining a specialized scraping infrastructure.
Website: https://serpapi.com
12. Scrappey
Scrappey is a developer-focused, pay-as-you-go scraping API that serves as a flexible ScrapingBee alternative. It specializes in simplifying complex data extraction tasks by bundling rotating proxies, full browser rendering, and sophisticated session handling mechanisms into a single solution. Its primary appeal lies in its straightforward metered pricing, eliminating the need for monthly subscriptions and making it suitable for projects with fluctuating or unpredictable workloads.
The platform provides robust headless browser capabilities, supporting over 30 browser actions like clicks, scrolls, and form submissions. This consistent interaction simulation, combined with sticky residential proxies and automatic retries on well-formed, authorized requests, helps maintain a high success rate against demanding targets. Scrappey also offers a cronjob scheduler with webhook delivery, automating recurring scraping tasks.
Key Features & Pricing
Scrappey's core strength is its simple, credit-based pricing model where users purchase a block of requests upfront. It also features session management and an integrated job scheduler for asynchronous scraping, which is a valuable addition for long-running tasks.
-
Pricing: Purely pay-as-you-go, starting at $20 for 25,000 requests. There are no monthly commitments or subscriptions.
-
Browser Actions: Automates interactions with Headless Chrome/Firefox, simulating human behavior to navigate dynamic sites.
-
Proxy Management: Built-in sticky residential and data center proxy rotation.
Pros and Cons
| Pros | Cons |
|---|---|
| No subscriptions; straightforward per-request pricing. | Pay-as-you-go requires estimating consumption upfront. |
| Quick ramp-up and strong concurrency for burst workloads. | Heavy browser interactions can consume credits quickly. |
| Public examples and ready-to-use scrapers are provided. | Lacks the enterprise-level support of larger platforms. |
Best Fit For
Scrappey is an excellent choice for developers, freelancers, and small teams who need a powerful scraping API without the commitment of a monthly plan. It excels in scenarios requiring automated browser actions, consistent interactions, and burst-heavy scraping tasks where a simple, pay-per-use model is more cost-effective.
Website: https://scrappey.com
Top 12 ScrapingBee Alternatives — Side-by-Side Comparison
| Product | Core features | Quality (★) | Pricing (💰) | Target (👥) | Unique (✨) |
|---|---|---|---|---|---|
| Scrappey 🏆 | Rotating proxies, headless rendering, session continuity, retries, REST API, concurrency & webhooks | ★★★★☆ Reliable throughput on JS-heavy pages | Contact for quote 💰💰 | 👥 Engineering & analytics teams at scale | ✨ Ease of integration, smart queueing, compliance guidance |
| Zyte | Rendered/unrendered modes, robust unblocking, success-based API | ★★★★☆ Enterprise-grade docs & support | Per-request tiers (success-based) 💰💰💰 | 👥 Teams needing granular control & predictable cost | ✨ Success-based billing; granular/unblock controls |
| Oxylabs | Target-specific Scraper APIs, Web Unblocker, premium proxy pools, JS rendering | ★★★★★ Enterprise reliability & scale | Transparent per-target plans (premium) 💰💰💰💰 | 👥 Enterprises & large-scale programs | ✨ Target-specific APIs + broad global proxies |
| Bright Data | Managed unblocking, Scraping Browser, retry handling, dataset marketplace | ★★★★★ Very large proxy/IP footprint | Premium / enterprise pricing 💰💰💰💰 | 👥 Teams needing managed unblocking & datasets | ✨ Web Unlocker + dataset marketplace |
| Smartproxy / Decodo | Site Unblocker, residential/ISP/mobile/DC proxies, session handling, geo-targeting | ★★★★☆ Strong US/EU performance | Flexible per-GB or per-request bundles 💰💰 | 👥 Mid-market / SMBs & quick onboard teams | ✨ Flexible billing; simple onboarding |
| Apify | Hosted Actors (store), SuperScraper API, scheduling, integrated proxies & webhooks | ★★★★ Fast to production with workflows | Credits + pay-as-you-go; free tier 💰💰 | 👥 Teams wanting ready-made scrapers & automation | ✨ Store Actors marketplace & workflow tools |
| ZenRows | Universal API (API+browser+proxies), success-based charging, concurrency & analytics | ★★★☆☆ Transparent but JS/proxy costs add up | One subscription; feature multipliers 💰💰💰 | 👥 Teams wanting single-subscription stack | ✨ Transparent per-feature multipliers |
| Crawlbase | Complexity-based quoting, JS/non-JS handling, success-based charging, cloud delivery | ★★★★ Intuitive cost estimator per target | PAYG by complexity; starter credits 💰💰 | 👥 Users who want per-target cost estimates | ✨ Complexity-based cost estimator |
| ScraperAPI | Proxy/rendering management, credit tiers, templates & SDKs | ★★★★ Straightforward onboarding & templates | Credit-based monthly tiers (100k–5M+) 💰💰 | 👥 Teams wanting predictable monthly tiers | ✨ Templates & structured-data endpoints |
| Scrapfly | Per-request credit breakdowns, budgets, browser rendering, residential proxies, debug tools | ★★★★ Developer-centric transparency | Credit plans; 1k free credits 💰💰 | 👥 Developers needing strict cost controls | ✨ Per-request cost headers & replay/debug tools |
| SerpAPI | Real-time SERP APIs (Search, Maps, Shopping, News), cached/success billing, high quotas | ★★★★★ Mature SERP parsing & SLAs | Clear monthly search quotas 💰💰💰 | 👥 SEO & marketing teams focused on SERP | ✨ Specialized SERP coverage & predictable quotas |
| Scrappey (PAYG) | Headless Chrome/Firefox, 30+ browser actions, human-behavior simulation, sticky proxies, cron + webhooks | ★★★★☆ Quick ramp-up & high concurrency | Pay-as-you-go per-1k requests; no subscription 💰💰 | 👥 Users needing metered browser interactions | ✨ Human-like actions (cursor/scrolling), ready scrapers |
Final Thoughts
Navigating the landscape of web scraping APIs reveals a crucial truth: there is no single "best" solution, only the one that best fits your specific project's needs. While ScrapingBee has established itself as a strong contender with its user-friendly API and powerful features, the diverse ecosystem of alternatives we've explored offers specialized capabilities that might be a more precise match for your use case, technical stack, or budget. The ideal ScrapingBee alternative for you hinges on a careful evaluation of your core requirements.
Key Takeaways for Choosing Your Scraping Tool
The journey from identifying a data source to successfully extracting it is filled with technical hurdles like CAPTCHAs, IP blocks, and dynamic JavaScript-rendered content. The tools we've covered, from Bright Data and Oxylabs to Apify and ZenRows, all aim to abstract away this complexity. However, they do so with different philosophies and pricing models.
Your decision should be guided by a few primary factors:
-
Scale and Complexity: Are you performing small, ad-hoc scrapes or building a large-scale, enterprise-grade data pipeline? For massive operations, platforms like Bright Data or Oxylabs, with their extensive proxy infrastructure and diverse product offerings, provide unparalleled scalability. For smaller projects, a more straightforward API like ScraperAPI or Scrapfly might offer a better balance of power and cost.
-
Target Site Specificity: If your primary goal is scraping search engine results pages (SERPs), a specialized tool like SerpAPI is purpose-built for the task, delivering structured JSON data without the need for manual parsing. Conversely, for scraping complex e-commerce sites with heavy JavaScript, a solution with advanced residential proxies and a robust browser rendering engine, such as ZenRows or Smartproxy's Decodo, is essential.
-
Developer Experience (DX): How important are comprehensive documentation, SDKs in your preferred language, and a clean API design? Platforms like Apify and Zyte excel here, offering extensive developer resources and pre-built actors or templates that can significantly accelerate your workflow.
-
Budget and Pricing Model: Do you prefer a predictable, subscription-based model, or a pay-as-you-go structure that aligns with variable usage? Carefully analyze the pricing tiers. Pay close attention to how credits are consumed, especially concerning features like JavaScript rendering, residential proxy usage, and handling of failed requests, as these can dramatically impact your final cost.
Implementation and Proxy Management
Once you select a tool, implementation success often comes down to understanding the nuances of web scraping. Even with a powerful API, you must consider ethical guidelines and the target website's terms of service. A critical component of this is your proxy strategy. While most of the services listed manage proxies for you, understanding the difference between datacenter, residential, and mobile proxies is vital for tackling difficult targets. For those looking to deepen their knowledge on specific proxy types crucial for advanced scraping, consider exploring this ultimate guide to residential proxies. This knowledge can help you make more informed decisions, whether you're using a fully managed service or building a more custom solution.
Ultimately, the best ScrapingBee alternative is the one that empowers you to access the data you need reliably, efficiently, and within your budget. Don't hesitate to leverage the free trials and starter plans offered by nearly every provider on this list. Real-world testing against your actual target websites is the most effective way to validate a tool's performance and determine if it's the right long-term partner for your data extraction needs.
Ready to experience a powerful and developer-friendly ScrapingBee alternative firsthand? Scrappey offers a robust API designed for high-success-rate data extraction, handling JavaScript rendering and proxy rotation seamlessly. Get started in minutes and see how our simple integration and reliable performance can streamline your web scraping projects.