
A Guide to Transparent Proxy Servers and How They Work
Ever heard of a transparent proxy server? It’s a type of intermediary that intercepts your internet connection without you ever having to lift a finger—no settings to change, no software to install. Unlike the proxies you might set up yourself, these operate invisibly right at the network level, automatically routing all your traffic.
This is usually done for things like filtering content, caching popular websites to speed things up, or just monitoring what’s happening on the network.
The Invisible Traffic Director
Think of it like this: you're driving down the highway, and without you even noticing, your car is briefly routed through a checkpoint. This checkpoint inspects your vehicle, maybe scans a sticker on the windshield, and then merges you right back onto the main road. You get to your destination totally unaware the detour even happened.
That's a transparent proxy in a nutshell. It sits between you and the internet, intercepting everything without any action needed on your part. To really get it, it helps to have a basic grasp of general proxy server setup first.
Core Functions of Transparent Proxies
These servers—often called "inline" or "intercepting" proxies—aren't built for your anonymity. Not at all. Network administrators are the ones who deploy them, mainly to enforce rules and keep traffic flowing smoothly.
Their main jobs usually fall into a few categories:
-
Content Filtering: Schools and corporate offices use them all the time to block access to certain websites or types of content. It’s how they make sure everyone sticks to the acceptable use policy.
-
Security Enforcement: They can act as a guard, scanning for malware or cutting off connections to known malicious sites. It’s an added layer of security for everyone on that network.
-
Bandwidth Optimization: By caching frequently accessed content (like popular web pages or big software updates), they can deliver it to users much faster and cut down on the network's overall internet usage.
The key takeaway is that transparent proxies are tools for network management, not user privacy. They are configured on the network router or firewall, making them mandatory for anyone using that network.
The rise of transparent proxies is part of a bigger trend. The global proxy market is expected to hit USD 5 billion by 2033, a significant jump from USD 2.51 billion, even as regulations like GDPR put tighter controls on how IP addresses are handled.
But while they have their place, their complete lack of anonymity is a massive headache for web scraping. Unlike a VPN that encrypts your connection and hides your IP, a transparent proxy actually forwards your original IP address straight to the target server. For a deeper dive on that, check out our guide on the key-differences-between-vpn-and-proxy-explained. This "transparency" is exactly why they’re a problem for most data extraction jobs.
How Different Proxy Types Handle Your IP Address
To see just how different transparent proxies are, it helps to compare them side-by-side with other common types. This table breaks down how each one handles your IP address and anonymity.
| Proxy Type | Anonymity Level | Original IP Visibility | Common Use Case |
|---|---|---|---|
| Transparent | None | Visible in HTTP headers | Content filtering, caching |
| Anonymous | Medium | Hidden, but proxy presence is known | General web browsing, bypassing blocks |
| Elite (High-Anon) | High | Hidden, proxy presence is hidden | Web scraping, privacy-sensitive tasks |
| Rotating | Very High | Hidden, IP changes frequently | Large-scale web scraping, distributed requests |
As you can see, transparent proxies are on the complete opposite end of the spectrum from what you’d want for anonymity. They announce your presence and your real IP, making them unsuitable for any task where privacy is a concern.
How Transparent Proxies Give Away Your Digital Footprint
Transparent proxies aren't sneaky by accident; they're designed to be, well, transparent. Their job is network management, not hiding who you are. This means they intentionally add specific bits of information to your web traffic, creating a crystal-clear digital footprint that points directly back to your original IP address.
For anyone in web scraping, getting a handle on this footprint is the first step to beating it.
These digital breadcrumbs are tucked right inside the HTTP headers of your requests. Think of HTTP headers as a little package of instructions and info sent with every connection you make. A transparent proxy intercepts this package and slips in a few extra notes telling the destination server, "Hey, this request came through me, but here’s where it really started."
This diagram shows the basic flow—the proxy sits in the middle, but it doesn't hide the starting point.
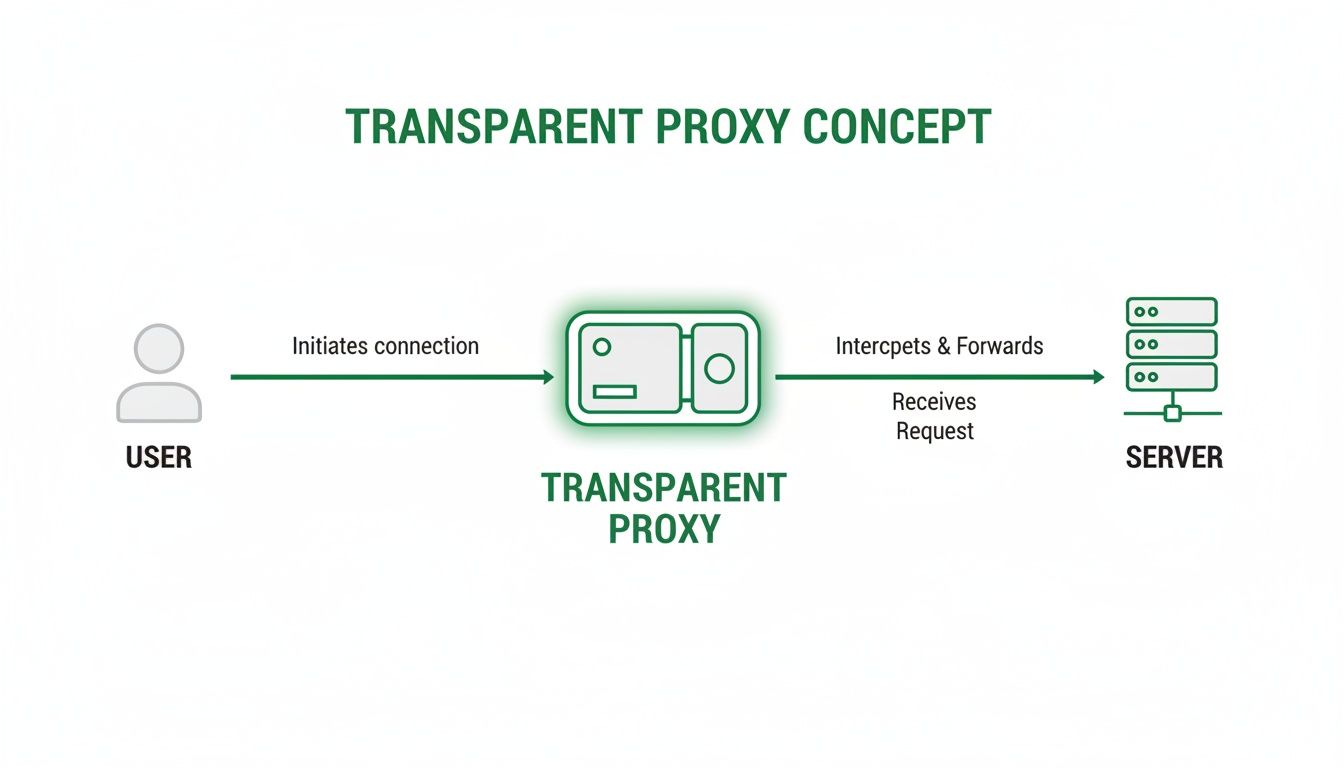
As you can see, the proxy intercepts the connection but does nothing to mask the fundamental path of identification.
The Telltale HTTP Headers
A few specific headers are notorious for blowing your cover when you're using a transparent proxy. Even if a proxy doesn't use all of them, just one is enough to kill your anonymity and get your scraper flagged by bot detection systems.
Here are the usual suspects:
-
X-Forwarded-For (XFF): This is the big one. It's explicitly designed to reveal the original IP address of a client connecting through a proxy. If your request hops through several proxies, this header can even hold a comma-separated list of every IP in the chain.
-
Via: The Via header is like a calling card left by the proxy. It announces that the request was forwarded and often includes details about the proxy server itself, like its software and version. This not only confirms you're using a proxy but can also help fingerprint its type.
-
X-Real-IP: Just like XFF, this header is another common way for proxies and load balancers to pass along the original IP address. It's one more direct giveaway of your true location.
A server doesn't need to play detective to figure out you're using a transparent proxy. The evidence is handed over in plain text with every single request, making detection a piece of cake for any modern web application firewall (WAF).
This kind of exposure has serious consequences for data collection. When a target website sees your real IP in an X-Forwarded-For header, it can easily enforce rate limits or issue a block that hits your actual network, not just the proxy. This is exactly why transparent proxies are unsuitable for web scraping tasks that demand any level of discretion or scale.
They create the illusion of being somewhere else while loudly broadcasting your real identity to the very systems you need to navigate carefully.
Why Do Transparent Proxies Even Exist?
Given that transparent proxies offer zero anonymity and happily announce your original IP address, it’s fair to wonder why anyone uses them at all. The answer is simple: they were never designed for privacy. Instead, transparent proxy servers are workhorse tools for network administration, security, and performance.
They are the silent gatekeepers of many networks you use every day, from corporate offices to the local coffee shop's Wi-Fi. Their job isn't to hide you; it's to control and streamline internet access for everyone on the network according to a set of predefined rules.
Common Real-World Applications
You’ll find these proxies in any environment where centralized control is a must. Because they require no configuration on the user's end, they’re perfect for enforcing network-wide policies without anyone having to lift a finger.
Here are the most common places you'll bump into them:
-
Corporate Networks: Companies use transparent proxies to enforce acceptable use policies, blocking sites like social media or streaming services to keep productivity up. They also scan traffic to stop malware and prevent sensitive company data from leaking out.
-
Educational Institutions: Schools and universities rely on them to create a safe online space for students. They filter inappropriate content and shield the network from threats, all without needing to configure thousands of individual laptops and phones.
-
Internet Service Providers (ISPs): Many ISPs use transparent proxies for caching. By storing local copies of popular content—think viral videos or big software updates—they can deliver it to you much faster and cut down on their own bandwidth costs.
The core idea behind a transparent proxy is enforcement, not evasion. It's a tool for network owners to manage their resources and secure their users, which is exactly why it's a direct roadblock for a web scraper trying to stay anonymous.
This critical role in network management has cemented their place in the global proxy server market. That market is booming, projected to hit USD 7.5 billion by 2033 with a hefty 12.8% compound annual growth rate as more organizations double down on network control. You can read more about the growing proxy server market dynamics and find additional insights.
Understanding these legitimate uses is key. When your scraper hits a transparent proxy, you haven't been singled out. You've just run into a standard, everyday piece of network infrastructure.
Web Scraping Challenges with Transparent Proxies
Trying to scrape a website with a transparent proxy is like being an undercover agent wearing a giant, flashing name tag. You might think you're disguised, but your real identity is right there for everyone to see. This complete lack of anonymity creates a minefield of problems for any serious data gathering operation.
The root of the problem is simple: transparent proxy servers dutifully pass your original IP address straight to the target website through HTTP headers. Modern bot detection systems are specifically designed to sniff out these kinds of signals. The moment they see a request with an X-Forwarded-For header showing your true IP, it’s game over.
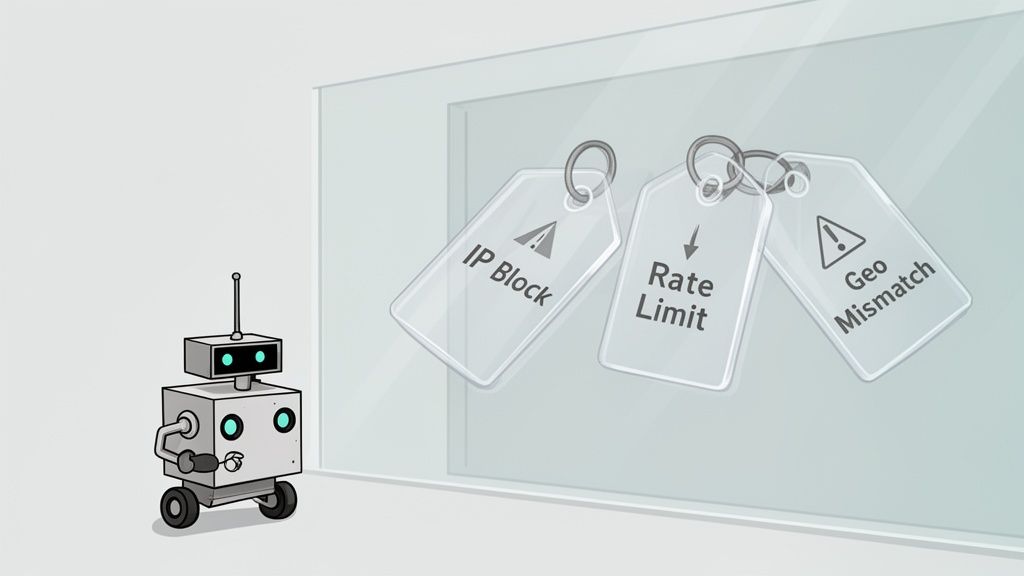
This exposure leads directly to a few common—and incredibly frustrating—failures that can bring your project to a screeching halt.
Immediate IP Blocks and Rate Limiting
The first and most obvious consequence is getting blocked. When a site’s security system flags your real IP, it won't just block the proxy you're using; it'll block you. That means even if you swap to a different proxy, the ban on your original IP might stick, cutting off your access entirely from that network.
Even if you dodge an outright ban, you'll almost certainly run into aggressive rate limiting. The website will apply its request limits to your original IP, not the proxy's. Your scraper will burn through its request allowance in no time, making any kind of large-scale scraping impossible. It’s a classic reason developers get stuck, wondering why their scraper keeps failing despite being routed through a proxy.
The critical mistake is assuming any proxy guarantees anonymity. With a transparent proxy, you aren't anonymous; you are simply being rerouted. The website sees both IPs—the proxy's and your own—making it trivial to connect the dots and shut you down.
Skewed and Inaccurate Geo-Targeted Data
Another huge headache is geo-targeting. Let's say you're using a proxy based in Germany to scrape local product prices. A transparent proxy will forward your request, but it will also tell the server you're actually connecting from, for example, the United States.
The target server sees both locations and either gets confused or just defaults to showing you content for your real location. The result? You end up collecting skewed, irrelevant, or totally wrong data. You’ll get US prices and shipping info instead of the German data you needed, completely compromising your dataset. For those diving into complex projects on large web applications you are authorized to access, understanding advanced proxy selection strategies can highlight just how critical proper proxy configuration is.
At the end of the day, the problem isn't that you're using a proxy—it's that you're using the wrong kind of proxy. While you might find plenty of options on various free proxy lists, a huge number of them are transparent and offer none of the anonymity required for reliable web scraping. Making this distinction is vital for building a scraper that actually works.
Building Resilient Scrapers That Handle Proxy Issues
Navigating the world of web scraping means building systems that can handle obstacles like transparent proxy servers. Since these proxies give away your real IP, the only real solution isn't to work with them—it's to handle them completely. Building a scraper that doesn't quit requires a total strategy shift, moving away from a single, static proxy to a smart, dynamic proxy network.
The whole point is to distribute your scraper’s traffic cleanly across many IPs instead of one exposed address. This means using high-anonymity proxies, like rotating residential or datacenter IPs, which don't leak your original IP. When you route requests through a massive pool of clean IPs, you get rid of the single point of failure that a transparent proxy creates.
Implementing a Robust Proxy Strategy
To keep requests reliable, your scraping logic needs to be intelligent and adaptive. Just swapping one proxy for another won’t cut it. You need a system that can manage sessions, handle failures gracefully, and rotate IPs with a purpose. This is where a dedicated web scraping API like Scrappey becomes a game-changer, handling all the messy proxy logistics for you automatically.
A truly resilient strategy has a few key parts:
-
Rotating High-Anonymity Proxies: Your setup should use a huge pool of residential or datacenter proxies. A good service will automatically swap these IPs with every request or session, making sure your scraper never builds up a suspicious history from one place.
-
Intelligent Session Management: For jobs that need a consistent identity—like clicking through a checkout process—you’ll want to use "sticky" sessions. This feature gives you a consistent IP for a specific amount of time before rotating, which keeps multi-step sessions coherent and predictable.
-
Automated Retry Logic: Web scraping is messy, and things will fail. Your system has to automatically retry failed requests using a different IP address and user-agent. This simple step ensures that a temporary network hiccup or a blocked IP doesn't bring your entire operation to a halt.
By outsourcing proxy management to a specialized service, you can get back to what matters: parsing data instead of fighting reliability issues. The platform takes care of IP rotation, header management, and retries, making your scraper stronger and far more reliable.
Geo-Targeting and Precise Configuration
When you’re scraping international websites, proper geo-targeting isn't just nice to have; it's essential. Using a proxy from the right country is the only way to access localized content, see accurate pricing, and view location-specific services. A transparent proxy completely ruins this by leaking your true location, but a solid proxy network lets you specify the country of origin for every single request.
This level of control ensures you get accurate, location-specific data, every single time. You can learn more about how Scrappey handles these challenges by checking out our documentation on the advanced session handling system, which details how to configure these features for the best results.
Scrappey Configuration for Effective Proxy Management
To put this into practice, here’s a quick look at how Scrappey's API parameters help you manage proxies without the headache. The idea is to offload the complexity so you can focus on your goals.
| Scrappey Feature | Configuration Tip | Why It Helps |
|---|---|---|
| Geo-Targeting | Use the proxyCountry parameter (e.g., 'proxyCountry': 'UnitedStates') to specify the proxy location. | Ensures you receive accurate, region-specific content, pricing, and services from the target website. |
| Session Management | Add a session ID to group requests. Use a unique ID for each user journey. | Maintains a consistent IP for multi-step processes, keeping sessions coherent and preventing session breaks. |
| Automatic Retries | Handled automatically by the API. If a request fails, it's retried with a new proxy. | Builds resilience by overcoming temporary IP blocks or network issues without manual intervention. |
| JavaScript Rendering | request.get renders dynamic pages in a real browser by default; use requestType: "request" for a fast non-rendered fetch. | Solves challenges presented by modern web apps, ensuring you get the complete, fully-rendered HTML content. |
By using these simple configurations, you can build a powerful and anonymous scraping workflow without ever having to manage a proxy list yourself.
To show you just how simple it is, here’s a Python example of a Scrappey API call. Notice how you just add simple flags for things like geo-targeting, while all the hard work of selecting and rotating proxies happens behind the scenes.
import requests
payload = { 'cmd': 'request.get', 'url': 'https://example.com/products', 'proxyCountry': 'UnitedStates' # Specify the geo-location for the request }
response = requests.post( 'https://publisher.scrappey.com/api/v1?key=YOUR_API_KEY', json=payload,
The API handles proxy rotation and headers automatically
)
Process the clean HTML data
print(response.text)
This is what a modern, resilient approach looks like. Instead of manually wrestling with a list of proxies that might be transparent, you use an intelligent system that guarantees anonymity and reliability. It’s how you build unstoppable scraping workflows.
Navigating the Murky Waters of Web Scraping Law
Look, the tech side of web scraping is only half the battle. The legal and ethical side of things is just as critical, and the type of proxy you choose plays a huge role in your risk profile.
It's an interesting quirk, but transparent proxy servers don't actually hide where you're coming from. Their whole purpose is to be, well, transparent. While this might sound like a good thing for compliance in some industries where traceability is key, for web scraping, it’s a massive technical weakness, not a legal shield.
Playing by the Rules
The real ethical weight comes down to how you use the heavy-duty tools, like anonymous or rotating proxies. Scraping responsibly isn't just about avoiding getting caught; it's about respecting the websites you visit and the privacy laws that protect people's data.
Before you kick off any scraping project, you absolutely have to consider:
-
Website Terms of Service: This is the rulebook for a website. It often spells out exactly what is and isn't okay when it comes to automated data collection. Ignoring this can get you blocked for good or even land you in legal hot water.
-
robots.txt Directives: Think of this file as the website's polite request for bots. While it's not a legally binding document, honoring its Disallow rules is a cornerstone of ethical scraping. It's just good digital etiquette.
-
Data Privacy Laws: Regulations like GDPR and CCPA are no joke. They have strict rules about collecting and handling personal data. You need to be certain your scraping isn't scooping up personally identifiable information without a solid legal reason.
Responsible scraping isn't just about hiding your tracks. It’s about being a good citizen of the web. Using powerful tools like Scrappey ethically means understanding that just because you can scrape something, doesn’t always mean you should.
At the end of the day, the goal is simple: gather the public data you need without causing headaches for the website owner, violating anyone's privacy, or breaking the law. Stick to these principles, and you'll protect not just your project, but the entire web ecosystem we all rely on.
Frequently Asked Questions
Got questions about transparent proxies? You're not the only one. Let's clear up some of the common points of confusion so you can avoid the usual headaches in your web scraping projects.
Can I Use a Transparent Proxy for Anonymous Web Scraping?
In a word: no. Transparent proxies are designed to be, well, transparent. They’re built to pass your real IP address right along to the destination server inside headers like X-Forwarded-For. That makes you completely visible.
If you need clean, reliable requests, you’ll have to go with a high-anonymity proxy. Think elite proxies or rotating residential proxies. Those are specifically engineered to hide your original IP, which is a non-negotiable for serious data collection.
How Can I Detect if I Am Behind a Transparent Proxy?
The easiest way is to use an online tool that inspects your HTTP headers. Hop onto any "What is my IP?" site that provides detailed header info. If you spot headers like Via or X-Forwarded-For and they contain your actual IP address, you’ve got your answer—you’re using a transparent proxy.
Remember, if a simple online tool can see both the proxy's IP and your own, so can the sophisticated bot detection systems on the websites you're trying to scrape. That’s a massive red flag.
Why Would My Scraper Get Blocked Using a Transparent Proxy?
It all comes down to those headers. Any website with decent security can read the information a transparent proxy adds to your request. When a server sees a request coming from a proxy's IP but also sees your home IP address tucked inside the X-Forwarded-For header, alarms go off.
This instantly flags your traffic as suspicious or automated. The site won't just block the proxy; it will often block your personal IP address, too, killing any future scraping attempts from your network. This is precisely why a high-anonymity service like Scrappey is essential for any reliable, large-scale scraping job.
Ready to build resilient scrapers that handle proxy issues and deliver clean data every time? Scrappey handles all the complex proxy logistics—from IP rotation to geo-targeting—so you can focus on results. Start scraping smarter today!