
A Developer's Guide to Rotating IP Address Proxy Mastery
So, you're a developer trying to scrape pricing data from some big e-commerce site. Your scraper kicks off, chugging along nicely, but then... silence. After just a handful of requests, it’s dead in the water. The website spotted the flood of activity from your single IP address and slammed the door shut. Sound familiar? It’s a classic, frustrating roadblock for anyone in the data game.
This is exactly where a rotating IP address proxy becomes your best friend.
What Is a Rotating IP Address Proxy and Why Does It Matter?
Instead of routing all your requests through one static, easily identifiable IP, a rotating proxy acts as a clever middleman. It has access to a massive pool of different IP addresses, and for each new request—or after a set amount of time—it automatically swaps out the IP you’re using.
Think of it like distributing your requests across many entrances instead of crowding through one. Spreading the load this way means no single IP carries all the traffic, so authorized targets are far less likely to rate-limit you. It's a simple way to keep large jobs running smoothly.
A rotating IP address proxy is basically a server that cycles through a fresh IP address from a huge pool for every connection you make. By distributing requests across many sources, it lowers the block rate on authorized targets, which makes it indispensable for reliable web scraping.
The Impact on Data Collection
This dynamic approach completely changes the game for anyone gathering data at scale. It’s what separates a scraper that works from one that constantly gets blocked, ensuring high success rates and reliability. It’s not some niche tool anymore; it’s a cornerstone of modern data engineering, especially for developers who rely on services like Scrappey.
By constantly changing the source of your requests, a rotating proxy distributes load across many addresses instead of hammering a target from one. This is the key to continuous, uninterrupted data extraction on sites you're authorized to access.
The demand for this technology has absolutely exploded. The rotating proxy market was valued at around $1.25 billion back in 2022 and is on track to nearly double by 2025. This surge is fueled by the relentless need for reliable data in fields like price monitoring and SEO intelligence, where scrapers using these proxies can hit success rates north of 95%. You can learn more about the growth of the proxy market on archivemarketresearch.com.
How IP Rotation Works Under the Hood
To get a handle on rotating IP proxies, picture the proxy server as a bustling switchboard operator. When your scraper sends out a request, it doesn't just fly straight to the target website. Nope, it first connects to this central proxy server, which cleverly acts as a middleman.
The server then dips into its massive pool of IPs—which can have thousands or even millions of addresses—and forwards your request using that fresh identity. The website you're targeting only sees the request coming from the proxy's IP, not yours, completely hiding your scraper's real origin. This all happens in a flash, milliseconds for every connection.
This core mechanism is what enables two main rotation strategies, each tailored for different kinds of data collection jobs.
The flowchart below gives you a visual of how this process helps a scraper sidestep blocks and grab the data it needs.
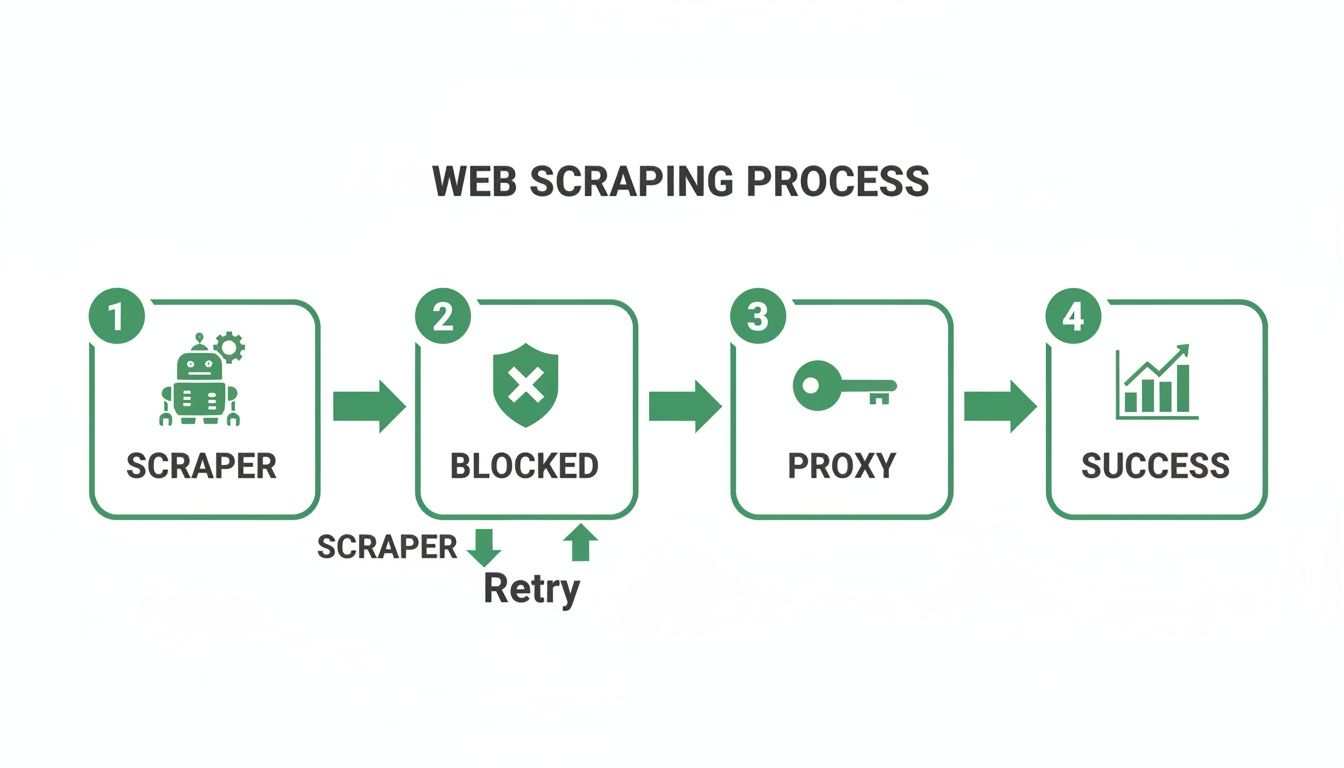
As you can see, the proxy is the critical gateway that turns a potential block into a successful request just by switching up the scraper's IP identity.
High-Frequency Rotation
High-frequency, or per-request, rotation is the go-to strategy for big, ambitious scraping projects. In this setup, the proxy server assigns a brand-new IP address for every single request your scraper sends out. It’s the most aggressive way to distribute load.
Imagine a huge crowd where each person asks a website just one question. The load is spread so thinly across hundreds of sources that no single address gets overwhelmed, which keeps request volume per IP well under typical rate limits.
This approach is perfect for tasks like:
-
Scraping thousands of product pages from an e-commerce giant.
-
Pulling search engine results for keyword analysis.
-
Gathering reviews from tons of different listings.
Sticky Sessions
On the other hand, some tasks need a bit more consistency. A sticky session holds onto the same IP address for a set amount of time—anywhere from a few seconds to several minutes—before it rotates. This makes sure that a series of related requests all look like they're coming from the same user.
Think of it like keeping one consistent address to complete a multi-step task, then moving on to a fresh one for the next batch. This is essential when you're navigating processes that depend on session continuity. If you're curious about the technical side, you can learn more in our guide on how to create a proxy server and its configurations.
Sticky sessions are vital for scraping scenarios that involve logging in, navigating through a checkout process, or filling out a multi-page form, where changing IPs mid-session would break the session or cause errors.
Rotating vs. Static Proxies: Which One Do You Need?
When you’re setting up a project that needs a proxy, you’ll quickly run into two main options: static and rotating. Both act as a middleman for your internet traffic, but they behave in fundamentally different ways. Picking the right one isn't just a small detail—it's critical for whether your project succeeds or fails.
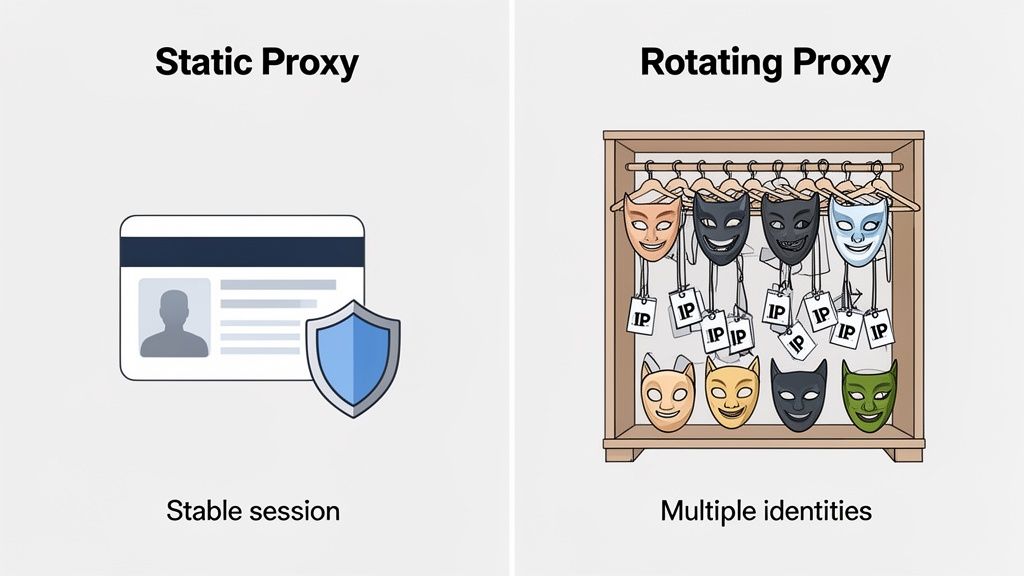
Think of a static proxy like a permanent digital ID card. It gives you one single, unchanging IP address that sticks with you for the long haul. This kind of stability is perfect when you need a consistent identity—say, for managing a social media account or always appearing to access a service from the same city.
On the other hand, a rotating IP address proxy gives you access to a massive pool of addresses. The proxy server automatically swaps out your IP address with every request you make or after a set amount of time. This dynamic approach is an absolute game-changer for large-scale data gathering, where distributing load and keeping per-IP request volume low is the top priority.
Rotating vs. Static IP Proxies at a Glance
To really get to the heart of the matter, it helps to see a direct comparison. The right choice boils down to a simple question: does your task need consistency or handling? This table breaks down the key differences.
| Attribute | Rotating IP Proxy | Static IP Proxy |
|---|---|---|
| Primary Use Case | Large-scale web scraping, SERP tracking, and price aggregation. | Account management, geo-unblocking, and stable session tasks. |
| IP Address | Changes with every request or on a timed basis. | Remains the same for a long duration. |
| Block Rate | Very low; distributes load across many IPs, so authorized targets are less likely to rate-limit. | Higher if request volume is too high from one IP. |
| Source Diversity | Very high; requests come from a broad pool rather than one address. | Moderate; presents a single consistent address. |
| Cost | Generally higher due to the large, managed IP pool. | More affordable for a single or small batch of IPs. |
Choosing between the two really depends on your project’s goals. For tasks requiring a stable, long-term identity, a static IP is cost-effective and reliable. But for anything involving high-volume requests where distributing load is key, a rotating proxy is the only way to go.
When to Go With a Rotating Proxy
If you're a developer working with a tool like Scrappey, the decision usually comes down to the scale and intensity of your scraping job. Firing off thousands—or even millions—of requests from a single static IP is a surefire way to hit rate limits almost instantly, since that volume of activity from one source overwhelms most servers. Always confine high-volume jobs to sites you're authorized to access, and respect their rate limits and Terms of Service.
For reliable, high-volume web scraping, a rotating IP address proxy isn't just a nice-to-have; it's the only way to get the job done right. By distributing your requests across a huge pool of IPs, you keep per-IP volume low and reduce blocked requests, ensuring a continuous stream of data on authorized targets.
This is exactly why rotating proxies are essential for tasks like comprehensive price monitoring, SEO analysis, or large-scale market research. The dynamic nature isn’t a bonus feature; it's a core requirement for success.
If you want to dive deeper into the different flavors of proxies out there, our documentation has a fantastic overview of datacenter proxies and where they fit into the picture.
Key Use Cases for Rotating Proxies
The tech behind rotating proxies is cool, but their real magic shines when you see what they can do. These tools are the secret sauce for some of the biggest data-gathering operations out there, turning frustrating roadblocks into a steady flow of valuable intel.
Whether you're an e-commerce giant or a scrappy startup, good data is what keeps you in the game. A rotating proxy is often the one thing that lets you get that data at scale, without the constant headache of getting your IP address blocked.
Large-Scale E-commerce Monitoring
Picture an analyst at an online retail company. Their job is to track the prices of 50,000 competitor products every single day. If they tried that with one IP address, their scraper would get shut down before it even scanned the first hundred items. It’s a complete non-starter.
This is exactly where a rotating IP address proxy saves the day.
By cycling through a massive pool of different IPs, the scraper distributes its requests across many addresses instead of concentrating them on one, keeping per-IP volume well within typical limits. This simple change unlocks the ability to:
-
Track Pricing: Keep a constant eye on what competitors are charging and adjust your own prices on the fly.
-
Monitor Inventory: Check stock levels to spot hot-selling products or find gaps in the market.
-
Analyze Product Catalogs: See what your rivals are selling to make smarter decisions about your own product lineup.
Without IP rotation, getting this kind of clear, real-time market view would be flat-out impossible.
SEO and SERP Tracking
For an SEO agency juggling hundreds of clients, checking keyword rankings across different cities and countries is a daily grind. Search engines like Google are smart; they can easily spot automated queries and will throw up CAPTCHAs or block an IP that’s making too many requests.
A rotating residential proxy is the go-to solution here. It lets the agency send search queries from IP addresses in specific places, so results reflect each location. Think checking "best pizza" from an IP in Chicago, then switching to a New York IP for the next search. This makes it possible to accurately track local and global search engine results pages (SERPs) while keeping request volume per IP low.
By distributing queries across diverse locations and respecting each engine's rate limits, rotating proxies provide the clean, location-accurate SERP data that SEO professionals need to measure performance and guide strategy effectively.
Market Research and Sentiment Analysis
Businesses also lean heavily on rotating proxies for market research, price intelligence, and using effective tools for competitor analysis. Imagine a research firm trying to gauge public feeling about a new product launch. They need to scrape thousands of comments and posts from a public platform they're authorized to access, which would trigger rate limits in a heartbeat from a single IP.
By distributing requests across different IPs and respecting the platform's rate limits, the firm can gather large amounts of public data reliably. This raw data can then be poured into sentiment analysis models to figure out what people really think, identify customer complaints, and spot trends before they go viral. It’s the difference between guessing from a small sample size and knowing from a comprehensive market overview.
Choosing the Right Type of Rotating Proxy
So you've decided a rotating IP is the way to go. Smart move. But not all rotating proxies are created equal. Your next big decision is picking between two main flavors: datacenter and residential. Nailing this choice can be the difference between a reliable web scraper and one that runs into frequent blocks.
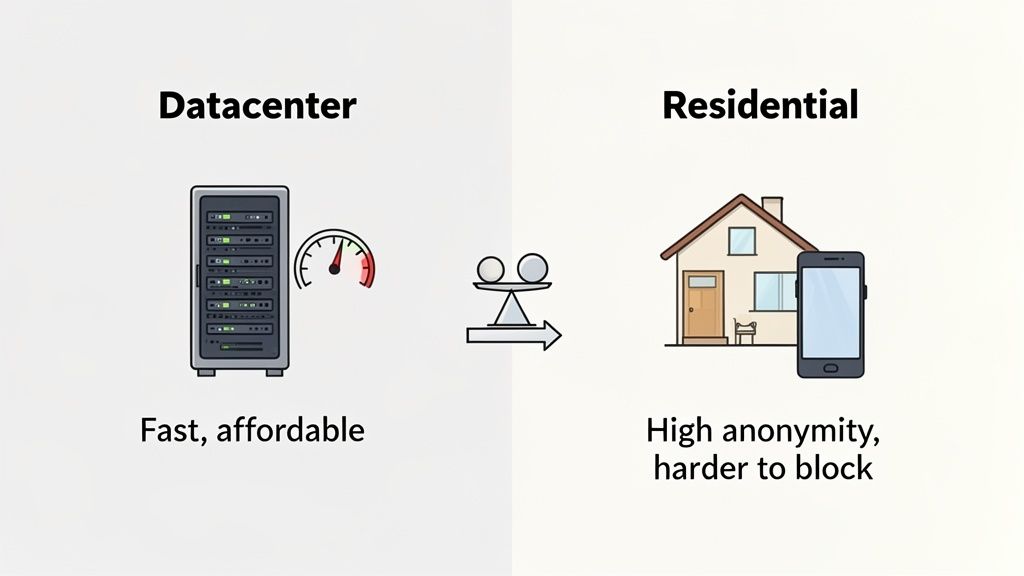
Think of datacenter proxies as the workhorses of the proxy world. These IPs are born in commercial data centers, making them incredibly fast, reliable, and easy on the wallet. But their origin is also their biggest weakness. Because all these IPs come from known server blocks, a savvy website can spot and block them without much trouble.
This makes them a great starting point for scraping less-protected websites or for any project where raw speed and low cost are your top priorities.
The Power of Residential Proxies
On the other side of the fence, you have residential proxies. These are the real deal—IPs sourced from actual Internet Service Providers (ISPs) and assigned to everyday devices like laptops and smartphones. To a target website, a request coming from a residential IP originates from an ordinary consumer connection.
That origin gives them a much lower block rate. They are the gold standard for working with demanding targets that deploy advanced bot detection systems. For things like headless browser scraping or pinpoint geo-targeting, high-quality residential proxies are pretty much non-negotiable if you want consistent results. You can check out Scrappey’s premium proxy options to see how they fit into a high-performance setup.
The core trade-off is simple: datacenter proxies give you speed and affordability, while residential proxies deliver a much lower block rate and higher success on demanding targets.
The market tells the same story. Residential rotating proxies have become a massive industry, valued at over 2 billion** in 2022 and on track to blow past **16 billion by 2030. Because they originate from ordinary consumer connections, they reach success rates between 90-99% on challenging sites, making them indispensable for high-stakes data gathering. You can read more about the rotating proxy market's growth on metastatinsight.com.
Ultimately, picking the right rotating proxy is all about matching its strengths to your project's specific needs. It's a balancing act between the level of consistent you require, your budget, and your performance goals.
Best Practices for Implementation and Integration
Getting a rotating IP proxy integrated into your web scraper is more than just plugging in some credentials. If you want high success rates and fewer headaches, you need a smart approach. The real goal is to build a scraper that’s not just effective, but also tough enough to handle errors and light enough on its feet to not get websites angry.
First thing's first: pace your requests. A scraper hammering a site with hundreds of requests a second from the same IP pool will quickly hit rate limits and can strain the target server. You've got to implement realistic delays and throttle your request rates. It's a simple step, but it distributes load responsibly and respects rate limits, which drastically reduces blocked or failed requests.
On top of that, graceful error handling isn't optional. Proxies will fail sometimes, and websites will throw errors. A well-built scraper expects this and comes prepared with a robust retry mechanism that uses exponential backoff. What this means is if a request fails, the scraper waits a bit before trying again, and it increases that wait time after each new failure. This keeps you from overwhelming the target server and gives your proxy pool time to cycle to a fresh IP.
Managing Your Scraper's Identity
Rotating IPs is just one piece of the puzzle. You also have to manage the other digital fingerprints that websites use to identify you. One of the most important is the User-Agent header, which basically tells the server what browser and operating system you’re on.
Using the same User-Agent for thousands of requests while your IP address changes constantly is inconsistent and can cause requests to fail. The best practice here is to rotate User-Agents right alongside your IP rotation. Keep a list of common, up-to-date User-Agent strings and cycle through them with each request. This keeps your request headers consistent with the connection they're sent from.
By combining User-Agent rotation with a rotating IP address proxy, you keep your client configuration consistent and improve reliability on authorized targets.
Session management is another key area. For multi-step tasks, like going through a checkout flow or filling out a form, you’ll want to use sticky sessions to keep the same IP for a short period. This gives you the consistency you need to complete the task without your scraper getting logged out or having its session killed halfway through.
Integrating with Scrapy
If you're using a popular framework like Scrapy, getting this all set up is pretty straightforward. The trick is to let middleware handle all the proxy logic for you, keeping it separate from your actual scraper.
-
Configure Middleware: Jump into your settings.py file and enable a proxy middleware. You can write a custom one or use a great library like scrapy-rotating-proxies.
-
Provide Proxy List: The middleware needs to know which proxies to use. You can define your list of proxy addresses right in settings.py.
-
Handle Retries: Use Scrapy’s built-in retry middleware to automatically manage any failed requests, making sure a new proxy is grabbed for each attempt.
This setup abstracts the messy rotation logic away from your spider code. It keeps your scraping logic clean and lets you focus on what really matters: extracting the data you need. Following these practices will help you build web scrapers that are more resilient, effective, and reliable.
FAQ
Got questions? We've got answers. Here are some of the most common things developers ask when they start working with rotating IP address proxies.
When Is IP Rotation Really Necessary?
IP rotation becomes a must-have the second your web scraping project grows beyond a few casual requests. If you’re just pulling a handful of pages once, you might slip by unnoticed.
But for serious tasks like daily price monitoring, tracking search engine results, or pulling massive datasets, constant rotation is your best friend. Without it, your scraper’s single IP will carry all the request volume and hit rate limits in no time. The rule of thumb is simple: if your per-IP request volume is high, you need rotation to distribute the load.
How Do Rotating Proxies Affect Performance?
Performance really depends on the type of rotating proxy you're using, and there's a bit of a trade-off to consider.
-
Datacenter Proxies: These are built for speed. Because they run on powerful servers in commercial data centers, they generally offer the fastest connection and highest bandwidth. They're perfect for scraping sites with basic security measures.
-
Residential Proxies: These might have a little more latency since they route your traffic through real home internet connections. But here’s the kicker: their ability to handle blocks is second to none, which often leads to much higher overall success rates on tough-to-scrape websites.
The slight dip in speed with residential proxies is almost always worth the massive boost in reliability. A successful request that’s a fraction of a second slower is infinitely better than a lightning-fast request that gets blocked.
Is Using Proxies for Web Scraping Legal?
For the most part, yes. Using a rotating IP address proxy to scrape publicly available data is generally legal. The key is to scrape responsibly and ethically.
This means you should always respect a site's robots.txt file, steer clear of collecting private or personally identifiable information (PII), and keep your request rate low enough that you don't overwhelm the website's servers.
However, the legal world can be tricky and laws change depending on where you are. It's always best practice to review a website’s terms of service and stick to ethical data collection to stay on the right side of the law.
Ready to build scrapers with fewer blocked requests? Scrappey provides a powerful API with premium rotating residential proxies and smart session handling built-in. Start collecting data from your authorized targets with unparalleled reliability today. Explore Scrappey's features and see the difference for yourself.